Data Classification Tools and Indian PII, The Gap That Matters
Date Published
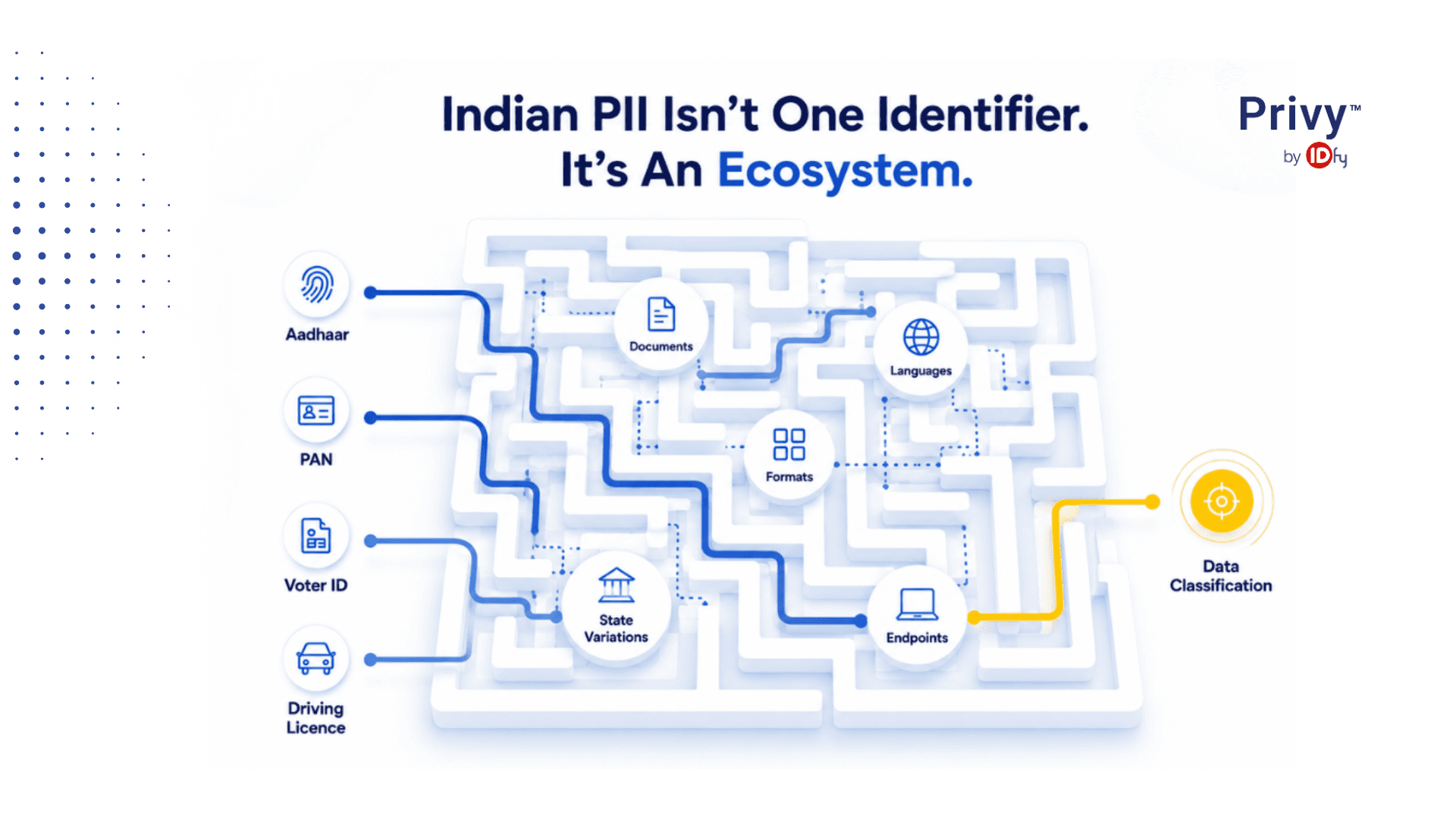
Data discovery and classification sit at the heart of DPDP compliance. Before an organisation can protect personal data, it needs to know what it holds, where it lives, and whether its controls are actually working. Does your current classification tool understand a Voter ID from Manipur?
When the Digital Personal Data Protection Act was passed, most organisations did what organisations do: they looked at what tools they already had and asked whether they were good enough. For many, the answer came from a vendor they had already deployed. A global data classification tool, usually built for GDPR or CCPA compliance, has now been quietly extended to cover India for DPDPA data classification with a new policy pack and a handful of added patterns. But what does 'extended to cover India' actually mean in practice?
In most cases, it means a 12-digit numeric pattern to catch Aadhaar, paired with the keyword 'Aadhaar'. A 10-character alphanumeric to catch PAN. Perhaps a phone number regex tuned to the +91 prefix. On a product page, this looks sufficient. In practice, it is one of the most consequential gaps in enterprise data governance in India.
Now take that Voter ID from Manipur. The identifier starts with a state-specific prefix that most global tools were never trained on. So when it appears in an HR system, in a field that simply says 'ID Proof', the tool sees an alphanumeric string it does not recognise and moves on without any flag or classification. That Manipur Voter ID is not a corner case; it shows the depth of Indian data. Recognising it takes an Indian data classification tool built for local data, not a global one extended with a policy pack.
The Structured Problem: Where Global Tools First Fall Short
Think about how many times a customer has shared their Aadhaar with your organisation. Now think about every system that touched it, like the onboarding platform, the KYC tool, the CRM, the analytics pipeline, and the HR system for your own employees. Each of those is a place where Indian personal data sits in a database, waiting to be discovered and classified. The question is whether your tool's PII detection actually recognises what it is looking at.
India's personal data landscape spans multiple government-issued identifiers, each with its own format logic, each appearing differently across systems and contexts. Let's understand some of them:
- Aadhaar is a 12-digit numeric identifier issued to over 1.38 billion residents. Most classification tools attempt to validate Aadhaar using the Verhoeff checksum, a mathematical algorithm that checks whether a 12-digit number has the structural properties of a genuine Aadhaar. The checksum tells you the number is structurally valid. It does not tell you whether it is actually an Aadhaar in this document, in this field, in this context. That distinction requires something the checksum cannot provide.
- PAN is a 10-character alphanumeric identifier where specific characters encode the taxpayer type and the first letter of the taxpayer's name. The structure is meaningful, but any similar-looking alphanumeric string can easily be classified as a PAN without proper contextual understanding. The false positive problem in pan classification here is significant.
- Voter ID carries state-specific prefixes, meaning an identifier from Maharashtra looks structurally different from one issued in Tamil Nadu. There is no single national format, only a pattern family with state-level variation that most global tools have no awareness of.
- A driving licence has no single national format at all. Each state transport authority follows its own convention, with differences in character count, delimiters, language, and composition.
These are just some of the critical identifiers. Each has format nuances. Each appears differently across structured fields and systems. When a classifier cannot accurately recognise these formats, it produces false negatives. Others produce a flood of false positives, flagging every 12-digit number as Aadhaar or every 10-character alphanumeric string as PAN.
In compliance terms, a false negative is undetected sensitive data exposure. A false positive is not being safe, as it is adding to the fatigue of compliance teams already drowning in noise in organisations that have chosen volume over accuracy as their default posture.
But what happens when that personal data does not live in a database field at all?
The Document Problem: Where the Gap Becomes a Chasm
A significant portion of Indian PII does not live in a CRM record or a structured database table. It lives in documents. Bank statements, loan applications, salary slips, land records, KYC documents, and insurance claim forms are business documents that contain sensitive personal data scattered across pages, sections, and fields in ways that tools built on text extraction and pattern matching are simply not designed to handle.
Consider a bank statement, one of the most common documents carrying personal and financial data in any Indian enterprise. A particular large private bank statement has a specific layout, header structure, and field organisation. A statement from a cooperative bank in rural Gujarat looks nothing like it. Same document type, completely different visual structure.
Then consider how PII appears within these documents. An Aadhaar number on a loan application may appear without spaces, without separators, as a continuous 12-digit string entered by a data entry operator. A form field might simply say "Government ID" with no specification, and an applicant may have entered a Voter ID, a Passport number, or a Driving Licence number depending on what they had available. The classifier has no label to work with, only the value itself, and must determine from context what it is looking at. Most tools cannot do this.
The complexity does not stop at business documents. The government-issued identity documents that form the backbone of Indian KYC carry their own version of this problem, arguably worse. The Aadhaar card, for instance, has gone through multiple design iterations since it was first introduced. The early version was an unusually long document with identifiers at the top, at the bottom, and on the reverse, showing the year of birth rather than a full date. In some states, the father's name appeared above the address; in others, it did not. Then came successive redesigns. Similarly, PAN cards have been in circulation for over twenty years, each generation looking different from the last. A tool trained on one version of these documents will miss another.
The scale of this problem is what makes it critical. KYC is not a niche process. It is a regulatory requirement across BFSI, telecom, insurance, and healthcare. This is not a marginal gap. It is a structural flaw.
The Compliance Gap No One Is Measuring
So what does this gap actually produce in practice?
An organisation deploys a classification tool. It scans their data estate. It returns a report. The report shows that personal data has been identified, classified, and inventoried. The compliance team reviews it, finds it satisfactory, and marks the exercise complete.
What the report does not show: the Aadhaar numbers in 40,000 scanned KYC PDFs the tool could not read. The PAN numbers in Hindi-language loan agreements are processed as unreadable text. The Voter IDs in HR documents that matched no pattern the tool recognised. The government IDs entered into open form fields were never classified because the label did not indicate what the value contained.
The organisation believes it is compliant. Its inventory is documented. Its controls are mapped to identified data. A meaningful portion of its actual personal data remains unclassified, unprotected, and invisible. Not because no one looked, but because the tool that looked was not built to see it.
Under DPDP's security safeguard obligations, this is not a technicality. It is a compliance failure that no amount of audit documentation will cover.
How Data Compass Changes What Is Possible
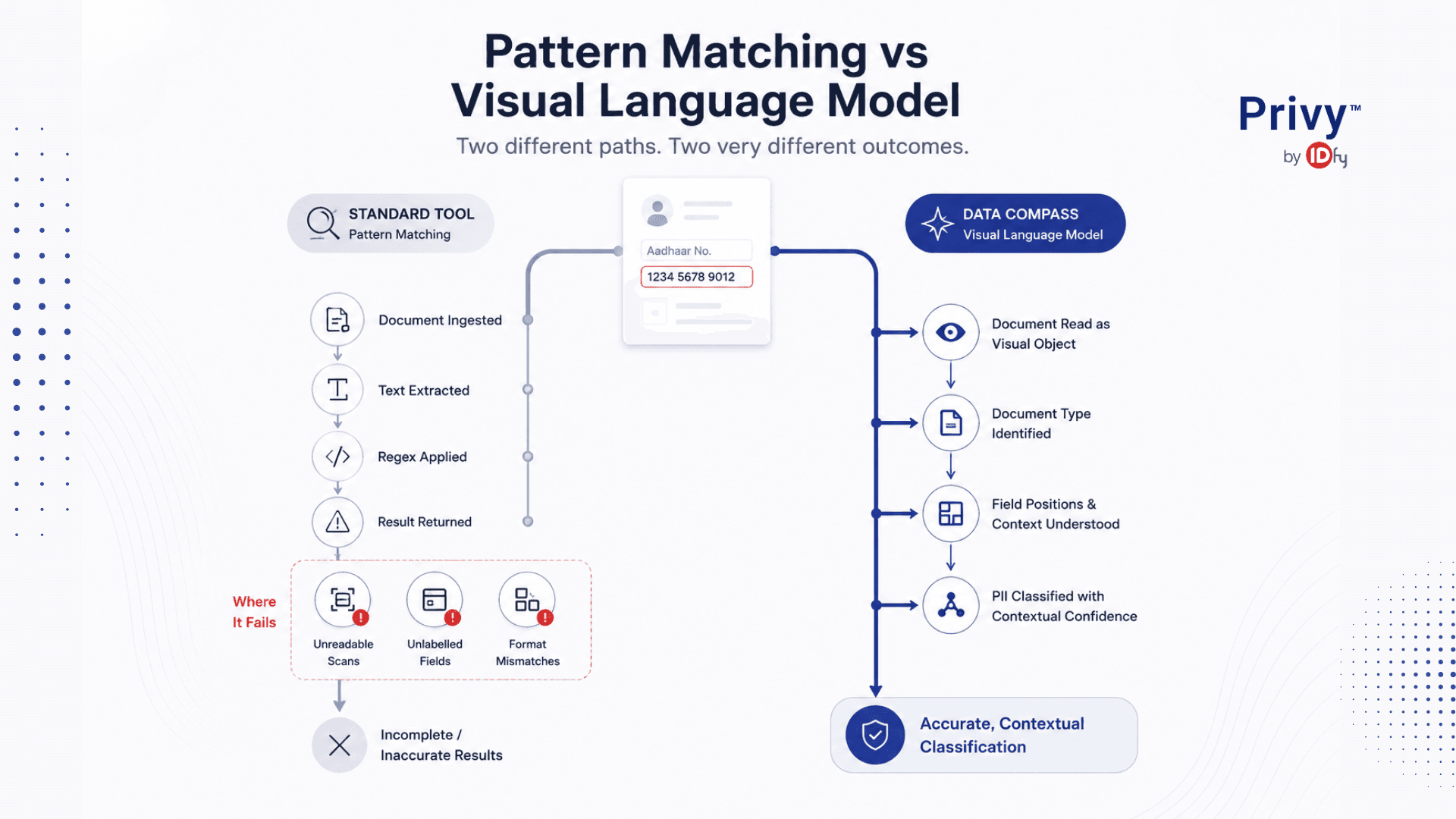
Accurate, sensitive data classification of PII embedded in Indian documents requires a fundamentally different approach from pattern matching on extracted text.
As an Indian data classification tool, Data Compass was built for Indian data, not adapted to just cover it. Built on over fifteen years of working with Indian PII across sectors, regions, formats, and their variability, it stands as the most accurate classification model in the country, not just for detecting Indian PII, but for recognising the documents it lives in.
Data Compass is built on document classification AI, a document visual language model that reads documents the way a human analyst would: visually, contextually, and with an understanding of document structure. Where conventional tools extract text and apply regular expressions, Data Compass processes the document as a visual object. It understands the document as a whole: the type of document, the section a number appears in, what surrounds it, and how the visual layout confirms or contradicts what a value claims to be. A 12-digit number that passes checksum validation means little in isolation, and as mentioned earlier, the Verhoeff checksum alone is not enough. When Data Compass encounters that same number inside a KYC form, positioned next to a name and a date of birth, it does not just validate the checksum. It recognises the document, understands the context, and produces a classification with real confidence behind it.
Beyond numbers and identifiers, it reads Devanagari, Tamil, Telugu, and other scripts natively, identifying PII in image-embedded fields that never get parsed as text at all. Critically, it recognises different versions of the same document. The 2010 Aadhaar card and the 2024 Aadhaar card are not the same visual object, and Data Compass knows the difference.
The coverage extends across 200+ connectors, including cloud storage, CRMs, HR systems, collaboration tools, shared drives, and endpoint devices. The perimeter is wide enough to include the surfaces where Indian PII actually lives, not just the systems organisations think to point a tool at.
The result is a classification inventory that an organisation can actually rely on. Not a confident report built on the data the tool could read, with an invisible gap underneath for the data it could not.
The Question Worth Sitting With
Most organisations that have run a classification exercise believe they have coverage. The report said so. The dashboard confirms it. The more honest question is what the tool did not see or what the tool misclassified. Not because it was poorly deployed, but because it was never designed to see Indian PII in the depth and variety that Indian enterprise environments actually produce.
Conclusion
DPDP compliance is not declared in a report. It is demonstrated when a regulator asks you to show, specifically and evidentially, how your customer data is protected across your systems. At that moment, the gap between what your tool classified and what actually exists in your data estate becomes visible.
The organisations that will answer that question confidently are the ones that started with a classification foundation built for Indian data. Not one that was extended to cover it.
If you're evaluating whether your current data classification capabilities can accurately identify Indian PII across your environment, reach out at shivani@idfy.com to explore how Privy by IDfy’s Data Compass can help strengthen your privacy and compliance foundation.
FAQ's
Why do global tools struggle with Indian PII detection?
They lean on pattern matching tuned for GDPR or CCPA. Indian identifiers like state-prefixed Voter IDs and format-encoded PAN need contextual recognition, so generic PII detection produces both false negatives and false positives.
What is document classification AI, and why does it matter for DPDP?
It reads a document as a visual object, its layout, context, and script, rather than extracting text and applying regex. For DPDPA data classification, that is what catches PII inside scanned KYC files, regional-language agreements, and image-embedded fields that text extraction never parses.
Can a generic tool handle PAN classification accurately?
Often not. PAN is a 10-character format where characters encode meaning, so any similar string can be misread. Accurate pan classification needs contextual understanding, not a regex on its own.
What counts as sensitive data exposure under the DPDP Act?
Personal data that stays unclassified and unprotected because the tool could not detect it. Under DPDP security safeguard obligations, undetected data is a compliance failure, not a technicality.
Do I need data classification levels for DPDP compliance?
Classifying by sensitivity helps you prioritise controls, but the prerequisite is accurate detection across structured systems, documents, and endpoints. An Indian data classification tool like Data Compass is built to recognise these formats and the documents they live in.

Unravel the nuances of Personal Data under the DPDP Act 2023, from Direct Identifiers like Aadhaar to quasi-identifiers like buying habits. Learn to shield your digital identity.

Learn why Data Security Posture Management (DSPM) is the new trust infrastructure for Indian businesses, with data discovery, mapping, & governance.