Data Discovery, Mapping and Governance Are The Foundation of DPDP Compliance
Date Published

The Hidden Problem Behind DPDP Compliance
Most enterprises approaching DPDP compliance start in the wrong place. They build consent banners, update privacy policies, appoint a Data Protection Officer, and call it progress. What they skip and what regulators will eventually ask about is a far more fundamental question: do you actually know what personal data you hold? For most organisations, the honest answer is no.
Data today doesn't sit neatly in one database waiting to be governed. It moves. A customer's phone number exists in your CRM, your support ticketing tool, three marketing automation exports, a legacy system no one has touched in years, and a spreadsheet someone downloaded six months ago. Your HR team processes employee Aadhaar details across payroll software, background verification tools, and onboarding forms. Your SaaS stack has grown faster than your visibility into it. This is the reality DPDP compliance runs into: not a lack of legal intent, but a lack of operational visibility.
Shadow data accumulates when teams adopt tools without IT oversight. Unstructured data - emails, PDFs, chat logs, scanned documents, carries sensitive PII that no one has mapped. AI tools ingest datasets in ways that create new data copies no one has accounted for, and the derived assets they produce - summaries, embeddings, transformed records carry the same DPDP obligations as the source data. Duplicate records live across systems with different retention timelines and different owners.
Consent cannot govern data that organisations cannot see. Purpose limitation cannot be enforced on data flows that no one has documented. Breach response cannot be fast or accurate when no one knows where the affected data resides. Spreadsheet-based tracking makes this worse. A data map built in a workshop will be wrong within weeks as new integrations go live and SaaS subscriptions change. Compliance drift - the gap between your documented position and your actual one widens every time the governance programme fails to keep pace with organisational change.
The answer is not more manual effort. It is a fundamentally different approach: one built on automation, continuous monitoring, and real-time visibility rather than periodic reviews and static documentation. That starts with knowing what data you actually hold.
Why Data Visibility Is a Core DPDP Requirement
The DPDP Act is not just a consent regulation. It creates accountability obligations that require organisations to know what personal data they process, why they process it, how long they retain it, who has access to it, and what happens when something goes wrong. Consider what that means across the key obligations. Personal data accountability requires that a Data Fiduciary can demonstrate responsible handling of all personal data in its possession. That is impossible without a complete inventory.
Purpose limitation means personal data collected for one reason cannot be used for another. Enforcing this requires knowing where each data asset lives and tracing it back to the purpose under which it was collected. Without mapped data flows, purpose limitation is just policy on paper. Data minimisation requires collecting only what is necessary. Organisations routinely discover, during a discovery exercise, that they hold far more data than any legitimate purpose requires. Minimisation begins with knowing what you have.
Breach response under DPDP requires timely notification and containment. Speed depends entirely on your ability to identify what was compromised, where it was stored, and who is affected. Without a mapped inventory, breach response becomes a scramble. Data retention obligations require the deletion of personal data when the purpose for processing has ended. Without visibility into where data exists and how long it has been there, retention policies remain aspirational.
Rights fulfilment; responding to access, correction, or erasure requests from Data Principals requires locating all instances of an individual's data across your systems within a reasonable timeframe. Fragmented, undiscovered data makes this operationally impossible at scale. Audit readiness demands documentary evidence that obligations are being met. That evidence starts with a complete, accurate, current view of your data landscape. DPDP compliance begins long before consent banners and privacy notices. It begins the moment you ask: Where is the data?
What Is Data Discovery?
Data discovery is the process of identifying and locating personal data across an organisation's systems, databases, cloud environments, SaaS tools, file servers, endpoints, emails, and third-party integrations. The goal is not simply to create a list of data sources. It is to build operational visibility: what categories of personal data exist, where they live, who owns them, who can access them, and what risks they carry.
Structured data discovery covers data held in databases, CRMs, ERP systems, data warehouses, cloud databases, and business applications where information follows a defined schema. This is typically easier to scan but is often underestimated in scope. Organisations routinely discover databases they had forgotten, shadow databases created by individual teams, and test environments still carrying real customer data. Discovery tools identify these repositories by reading metadata - table names, column headers, data types, and system attributes before scanning the data itself.
Unstructured data discovery is where most compliance programmes fall short. Unstructured data, such as emails, PDFs, Word documents, scanned forms, chat archives, and log files, often contains the most sensitive personal information and is the hardest to find, classify, and govern. Discovery typically relies on metadata analysis such as file names, file types, locations, ownership, creation dates, modification history, repository attributes, etc to establish visibility into the organisation's unstructured data estate. A scanned KYC form sitting in a shared drive carries the same compliance obligation as a structured record in your core database. Discovery processes must cover both.
Effective discovery must span the entire enterprise data estate, including cloud environments, on-premises infrastructure, SaaS applications, endpoints, shared drives, collaboration platforms and third-party systems. Personal data is rarely confined to a single environment. Continuous discovery provides a consolidated inventory of data assets regardless of where they reside, creating the visibility required for downstream classification, mapping and governance activities.
Data Classification: Turning Raw Discovery Into Governance
Discovery finds data. Classification determines what PII is present and what the risk is associated with the business context. Without classification, you have a list of data assets but no way to prioritise controls, assign governance obligations, or differentiate between a routine operational record and a file containing health and financial information. Classification is what turns raw inventory into actionable governance.
What warrants heightened governance attention under DPDP? Unlike GDPR, which enumerates specific special categories of personal data, DPDP takes a more open-ended approach, leaving room for the government to notify additional categories over time. That framing of explicit sensitive data categories existed under the older IT (Reasonable Security Practices) Rules, 2011, but was not carried forward in the same form.
The DPDP Act 2023 carries explicit obligations around children's data and grants the government power to notify additional categories as enforcement matures. As a governance posture, enterprises are prudently applying stronger controls to data types that carry the greatest potential for harm: financial records, health and medical information, biometric data, official identifiers such as Aadhaar and PAN, authentication credentials, and data concerning minors. This is sound risk governance, even where the regulatory categorisation continues to evolve. Classification by sensitivity and business context means tagging each data asset not just by what it contains, but by why it exists and what risk it creates. A customer's name in a support ticket has a different risk profile from the same name attached to a medical consultation record. Context shapes governance requirements.
Risk tiering allows organisations to prioritise. Not all personal data carries the same sensitivity or regulatory significance. Tiering by sensitivity, volume, access breadth, retention age, and third-party sharing helps direct governance effort where it matters most.
Why does manual classification break at scale? In a small organisation with a handful of systems, manual classification is feasible. In an enterprise with hundreds of data sources, thousands of files, and continuous data creation, it is not. Manual classification is slow, inconsistent, and dependent on individuals who may lack the context to classify accurately. Most automated tools don't fully solve this either. They address the volume problem but introduce gaps of their own.
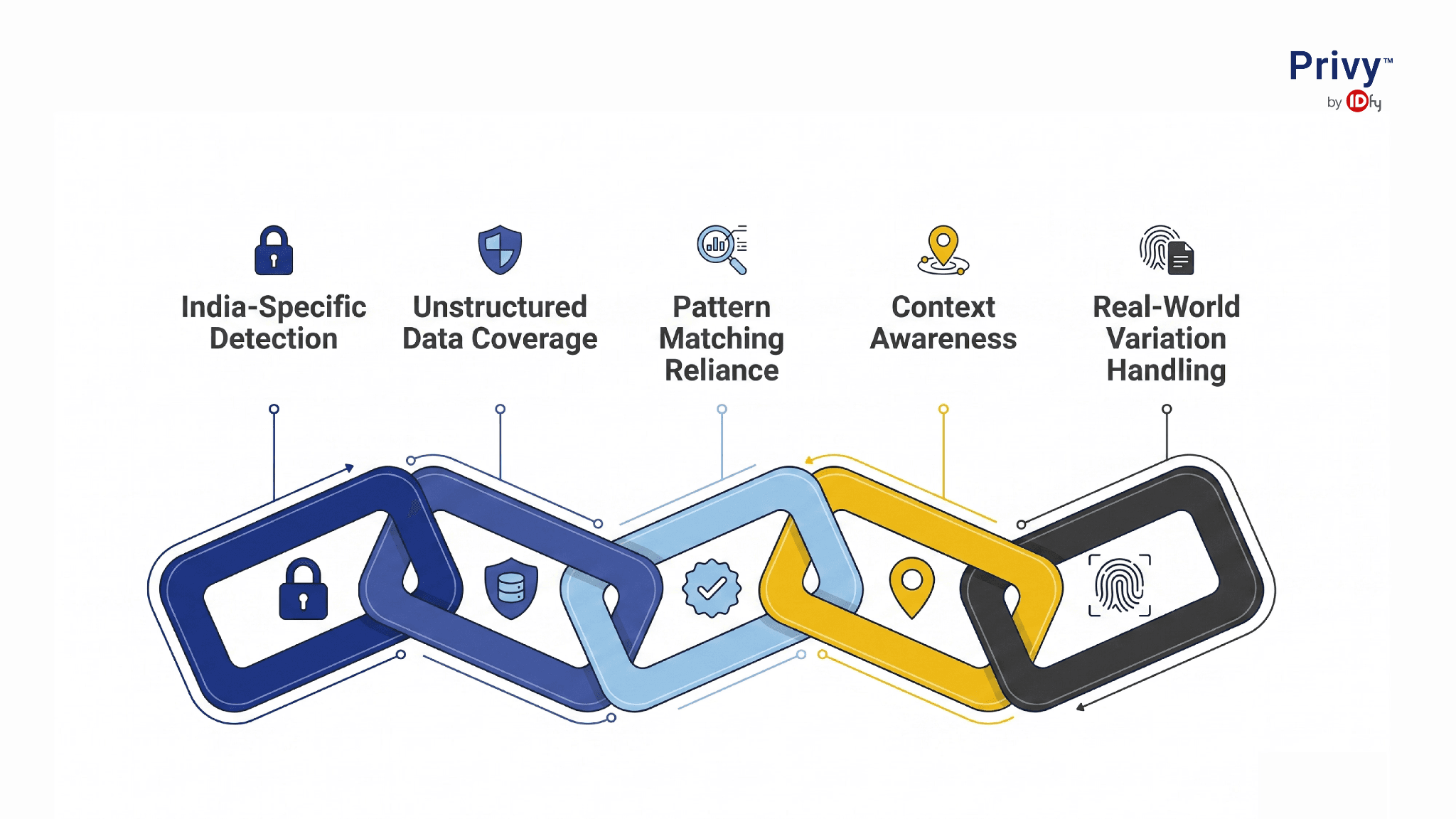
- Limited India-specific detection. Most classification tools are optimised for global frameworks and struggle with identifiers common in Indian enterprise environments- Aadhaar numbers, PAN details, voter IDs, driving licence records, UPI-linked information. These aren't edge cases. They're the core of what DPDP governs.
- Weak coverage of unstructured data. Most solutions perform well on structured databases but fall short when personal data is embedded in emails, PDFs, scanned forms, chat logs, and business documents where information doesn't follow a consistent format.
- Over-reliance on pattern matching. Traditional classification engines depend on predefined rules and regular expressions. They miss partially masked identifiers, free-text references, and non-standard representations, the kinds of variations that appear constantly in real enterprise data.
- No context-awareness. The same data element can carry different governance implications depending on how and why it is being processed. Most tools identify what data exists but not what it means in context.
- Poor handling of real-world variation. Enterprise data rarely follows perfect patterns. Personal data appears across multiple languages, abbreviated formats, handwritten records, OCR-generated text, and legacy documents. Rigid detection logic produces missed detections and inconsistent outcomes at scale.
Classification is not a one-time exercise. As new data enters the organisation, it needs to be classified. As systems evolve and data moves, classifications need to be reviewed. Automated classification with continuous monitoring is the only approach that scales with enterprise data growth.
What Is Data Mapping? And Why Static Mapping Fails
Once you know where data exists, you need to understand how it moves. That is what data mapping does. Data mapping traces the flow of personal data throughout your organisation: where it enters, how it is processed, which systems it touches, which teams handle it, which third parties receive it, and where it eventually ends up or gets deleted. A good data map tells you not just where data sits, but where it travels and that distinction matters enormously for compliance.
A customer's email address, for example, does not just live in your CRM. It may be synced to your marketing automation platform, shared with a third-party email delivery service, exported by your analytics team, passed to a support tool via API, and copied into a finance system for invoicing. Each of those flows carries compliance implications: Is there a valid purpose for each transfer? Are third parties under appropriate contractual obligations? Mapping makes these flows visible. Without it, purpose limitation, vendor governance, and cross-border transfer obligations remain ungovernable. Why static mapping fails. The traditional approach is a spreadsheet or Register of Processing Activities (RoPA) built in a workshop and updated annually. The problem is that organisational data flows do not stay static. New SaaS tools get connected via API. Teams build new workflows. Vendors change their data handling practices. AI integrations create data pipelines that did not exist last quarter.
A static map becomes inaccurate the day after it is built. By the time it is reviewed again, it may bear little resemblance to your actual data landscape. Relying on it for audit responses, rights fulfilment, or breach investigations introduces serious governance risk.
Dynamic data mapping continuously updates the map as systems, integrations, and workflows change. It draws from actual system connections, API logs, and data flow signals rather than relying on manual input. The result is a map that reflects your data reality in near real-time rather than a historical snapshot. For organisations with significant SaaS adoption, cloud infrastructure, and third-party vendor ecosystems, dynamic mapping is not a premium feature. It is a compliance necessity.
From Discovery to Governance: Building a Personal Data Inventory
Discovery and classification are inputs. What they produce when connected into a coherent structure is a personal data inventory. A personal data inventory is a centralized, structured record of all personal data an organisation processes: what data exists, where it lives, who owns it, what purpose it serves, how long it is retained, and which third parties it flows to. It is the operational backbone of a privacy programme.
Without a complete inventory, privacy operations are reactive. Teams search manually across systems for every Data Principal request. Audit preparation becomes a scramble for information that should already be centralised. Retention policies are applied inconsistently. Governance accountability is diffuse. With a complete, current inventory, rights requests can be fulfilled accurately. Retention can be automated. Audit evidence is available on demand rather than assembled under pressure.
Data lineage extends the inventory into the time dimension, where data came from, how it has been transformed, and where it is going. This is particularly important for demonstrating purpose limitation: you can show that data collected for onboarding was not subsequently used for marketing, because the lineage shows no flow between those processing activities. Ownership assignment becomes possible once the inventory exists. Each data asset should have a designated owner accountable for its accuracy, retention, and access controls. Without the inventory, ownership is assumed. With it, accountability can be formally assigned and tracked.
The inventory does not have to be built all at once. Organisations typically start with their highest-risk data categories and highest-volume systems, then extend coverage over time. What matters is that it exists, stays current, and drives actual governance decisions.
DSPM and Automated Privacy Governance
Data Security Posture Management (DSPM) transforms data visibility into risk visibility. By continuously monitoring access, exposure, security controls, retention posture and data handling practices, DSPM enables organisations to identify and prioritise the risks associated with sensitive personal data.
Where traditional governance programmes rely on periodic audits and manually maintained records, DSPM provides continuous, automated visibility into where sensitive data exists, how it is protected, and where it is exposed. It does not replace governance. It makes governance operational at the scale modern enterprises require.
DSPM platforms continuously scan data environments, cloud storage, databases, SaaS integrations, APIs, unstructured repositories, and evaluate risk across six dimensions.
- Access risk. Who can access sensitive data, and is that access justified? DSPM identifies over-permissioned datasets, excessive privilege, dormant accounts, and orphaned access rights that increase the likelihood of unauthorised access.
- Data exposure risk. Is sensitive data publicly accessible, unencrypted, or stored insecurely? DSPM monitors for misconfigured storage, exposed repositories, and unsecured backups.
- Unmanaged duplication risk. Personal data gets replicated across analytics platforms, testing environments, backups, and AI systems. DSPM identifies copies that exist outside governance controls and flags whether they are appropriately protected and owned.
- Retention and lifecycle risk. Is personal data being held longer than its purpose requires? DSPM surfaces datasets that exceed retention policies or persist in inactive systems after business use has ended.
- Third-party and ecosystem risk. Which vendors, SaaS platforms, and external systems have access to personal data? DSPM provides visibility into data shared beyond the enterprise boundary and into whether governance controls remain consistent there.
- Cross-border and AI-derived data risk. As data moves across cloud regions and global platforms, DSPM identifies transfers that may create jurisdictional exposure. It also covers AI-derived assets — summaries, embeddings, vector stores — that carry DPDP obligations but rarely appear in governance records.
DSPM platforms maintain an ongoing picture of the data landscape without requiring manual intervention. New SaaS integrations are detected, new sensitive data stores are flagged, and data flows that were not previously documented get surfaced as they emerge. ML models extend this across data volumes no human team could manually review, identifying PII, flagging high-risk patterns, and surfacing anomalies for review rather than requiring the compliance team to find them.
Governance orchestration closes the loop between visibility and action: triggering retention workflows, generating audit-ready reports, alerting data owners to risks, and integrating with incident response. For Indian enterprises under DPDP, this matters because the Act requires ongoing accountability, not a one-time exercise. DSPM is the infrastructure layer that makes that operationally possible.
Privacy Enhancing Technologies: Applying the Right Protection
Discovery, classification, mapping, and DSPM help organisations understand what data they hold, how it moves, and where it is exposed. The next step is protection. Privacy Enhancing Technologies allow organisations to reduce privacy and security risk by applying controls appropriate to the sensitivity, purpose, and exposure of personal data.
Common PETs include encryption to protect data at rest and in transit; masking to limit unnecessary visibility of sensitive information; tokenisation to replace sensitive identifiers with non-sensitive substitutes while preserving business functionality; pseudonymisation to remove direct identifiers while maintaining controlled linkage to source records; anonymisation to irreversibly reduce identifiability for analytics and sharing use cases; and synthetic data to enable testing, AI development, and analytics without exposing real individuals' information.
The right PET depends on the type of data, its processing purpose, how frequently it is accessed, and the risks identified through governance and DSPM processes. Effective privacy programmes move beyond visibility alone, applying risk-based protections that align with the context in which personal data is collected, shared, and processed.
What a Modern DPDP Governance Stack Looks Like
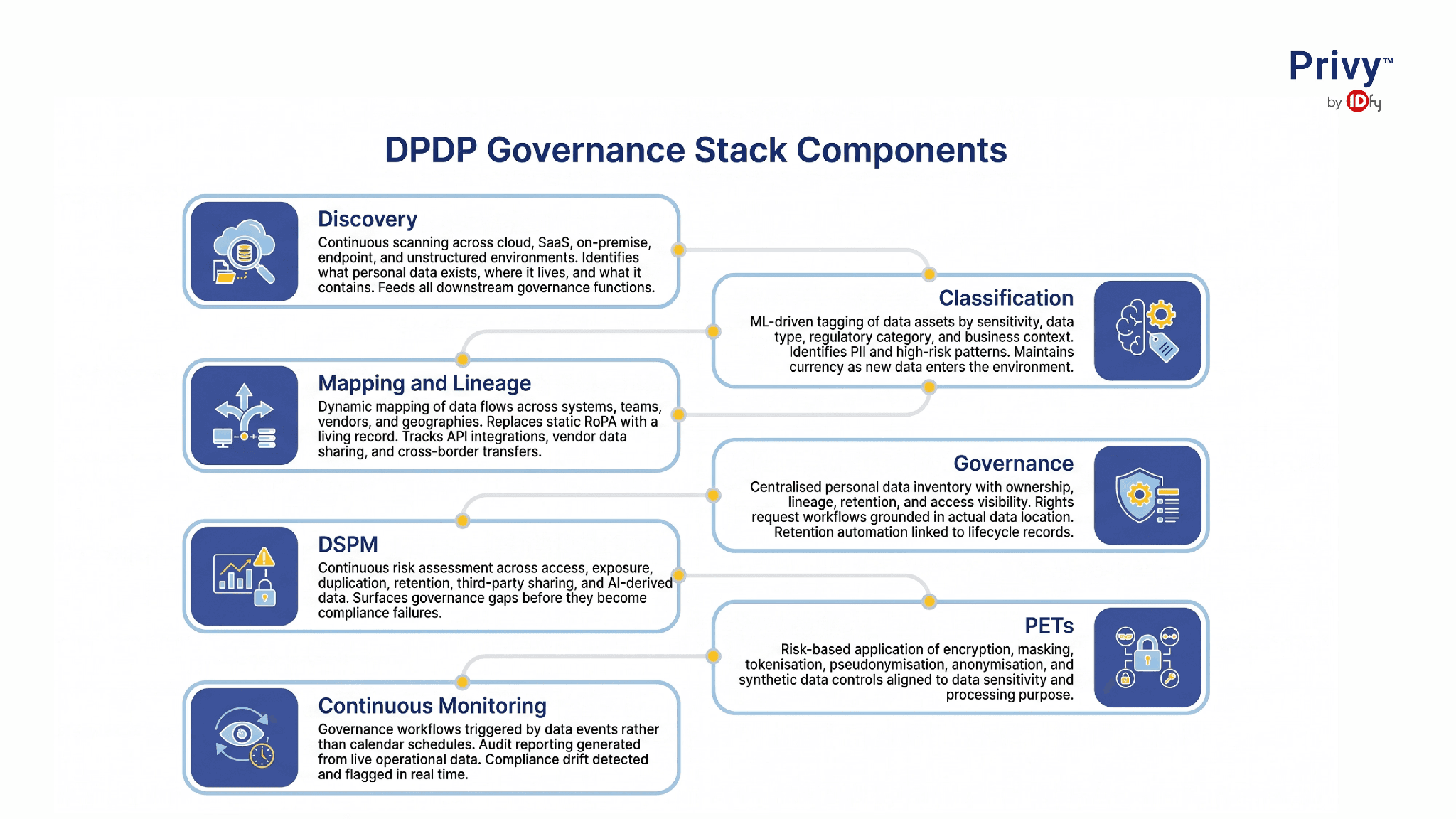
A mature DPDP governance programme is not a single tool or a single team. It is a stack of capabilities that work together to provide visibility, control, and accountability across the data lifecycle.
Discovery - Continuous scanning across cloud, SaaS, on-premise, endpoint, and unstructured environments. Identifies what personal data exists, where it lives, and what it contains. Feeds all downstream governance functions.
Classification - ML-driven tagging of data assets by sensitivity, data type, regulatory category, and business context. Identifies PII and high-risk patterns. Maintains currency as new data enters the environment.
Mapping and Lineage - Dynamic mapping of data flows across systems, teams, vendors, and geographies. Replaces static RoPA with a living record. Tracks API integrations, vendor data sharing, and cross-border transfers.
Governance - Centralised personal data inventory with ownership, lineage, retention, and access visibility. Rights request workflows grounded in actual data location. Retention automation linked to lifecycle records.
DSPM - Continuous risk assessment across access, exposure, duplication, retention, third-party sharing, and AI-derived data. Surfaces governance gaps before they become compliance failures.
PETs - Risk-based application of encryption, masking, tokenisation, pseudonymisation, anonymisation, and synthetic data controls aligned to data sensitivity and processing purpose.
Continuous Monitoring - Governance workflows triggered by data events rather than calendar schedules. Audit reporting generated from live operational data. Compliance drift detected and flagged in real time.
This stack does not require replacing every existing system. It requires connecting visibility and governance functions so that decisions are made on current, accurate information. Platforms like Privy by IDfy are built to provide this connected layer — discovery, classification, mapping, and governance in one operational view, designed specifically for the DPDP compliance reality of Indian enterprises.
Industry-Specific Governance Challenges
Data governance is not generic. Different sectors carry different risk profiles, data volumes, and compliance pressures.
Banking and Financial Services sit at the intersection of DPDP, RBI data localisation requirements, and sectoral governance norms. Banks process large volumes of personal data - KYC documents, financial transaction records, credit histories, biometric authentication data across core banking systems, digital channels, fintech integrations, and customer support infrastructure. Governance programmes here must navigate retention complexity (where regulatory hold requirements can conflict with minimisation obligations), vendor data sharing across payment networks and credit bureaus, and the challenge of governing legacy systems never designed with privacy in mind.
Healthcare and Health Apps process some of the most sensitive personal data in scope; medical records, diagnostic data, prescription histories, and mental health information. Health app operators face governance challenges around consent granularity, retention timelines tied to clinical rather than transactional needs, and data sharing with insurers, labs, and hospital networks.
EdTech Platforms handle data concerning children and young adults - a category that attracts explicit obligations under DPDP, including requirements around verifiable parental consent. Student data governance must account for minimisation relative to educational purposes, retention tied to the academic lifecycle, and restrictions on behavioural profiling.
Insurance processes health, financial, and biometric data across the policy lifecycle — underwriting, claims, and settlement. Data sharing with TPAs, surveyors, and reinsurers creates vendor governance complexity that most programmes underestimate.
Telecom operators handle call records, location data, device identifiers, and usage patterns at scale. Data localisation requirements and cross-border transfer exposure through global platforms make governance both technically demanding and high-stakes.
E-commerce and Retail generate continuous streams of behavioural data, purchase histories, and payment records. Data collected for order fulfilment routinely flows into marketing and personalisation workflows; governing those secondary uses is a core DPDP challenge.
HR and Workforce Technology platforms process Aadhaar, PAN, payroll records, background verification outputs, and health declarations. Employee data governance is consistently the most overlooked gap in enterprise DPDP programmes.
Government and Public Sector Undertakings process citizen data at a scale no private enterprise matches. Legacy infrastructure, inter-departmental data sharing, and the dual role of regulator and data controller create governance challenges unique to the sector.
Third-Party Vendor Ecosystems create governance complexity regardless of sector. Most enterprises share personal data with dozens of vendors, cloud providers, analytics platforms, payment processors, HR software, and marketing tools. Each sharing relationship is a data flow that must be mapped, governed, and documented. Vendor onboarding without a data governance assessment is a gap that DPDP's accountability provisions directly address.
Building a DPDP-Ready Data Governance Programme
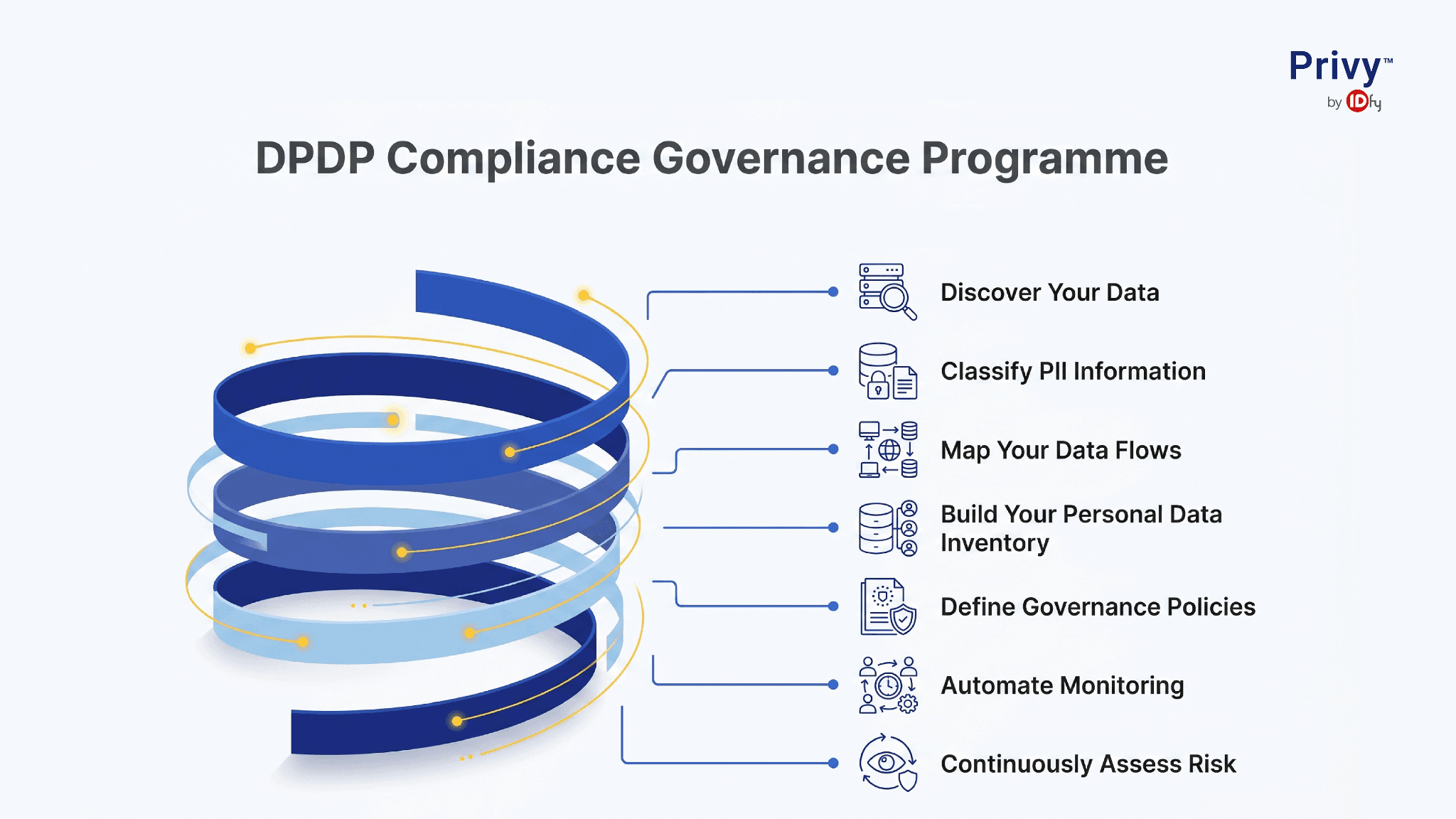
A governance programme that can withstand DPDP scrutiny is built in stages, with each stage extending both visibility and control.
Step 1: Discover your data. Run a discovery exercise across your highest-risk environments first, customer-facing databases, HR systems, marketing platforms, and known sensitive data repositories. Use automated scanning tools to cover unstructured data and shadow repositories that manual interviews will miss.
Step 2: Classify PII information. Apply classification logic to tag data assets by sensitivity, data type, and regulatory category. Use ML-assisted classification for data volumes that manual review cannot handle. Establish a classification taxonomy that maps to DPDP's obligations and your internal governance requirements.
Step 3: Map your data flows. Build a dynamic map of how personal data moves through your organisation between systems, teams, vendors, and geographies. Document processing purposes for each flow. Flag flows that lack adequate legal basis or contractual coverage.
Step 4: Build your personal data inventory. Consolidate discovery, classification, and mapping outputs into a centralised inventory. Assign ownership. Record retention timelines, access permissions, and processing purposes. Keep it current through automated updates.
Step 5: Define governance policies. Translate DPDP obligations and organisational risk tolerance into operational policies: retention schedules, access controls, data minimisation standards, third-party sharing rules, and incident response protocols.
Step 6: Automate monitoring. Replace periodic compliance reviews with continuous monitoring. Implement alerts for classification anomalies, retention policy breaches, access over-permissions, and new undocumented data flows.
Step 7: Continuously assess risk. Run ongoing privacy impact assessments for high-risk processing activities. Use DSPM exposure data to prioritise governance attention. Treat risk assessment as an input to governance decisions, not a separate compliance exercise.
Common Mistakes Enterprises Make
Organisations that have been through a DPDP readiness assessment tend to encounter the same failure modes.
Treating discovery as a one-time exercise. A discovery project that runs once and sits as a historical document provides false assurance. Data landscapes change continuously.
Relying on spreadsheets. Spreadsheet-based data maps start out inaccurate and get worse. They are a starting point, not a governance infrastructure.
Focusing only on consent. Consent management addresses one DPDP obligation. Accountability, minimisation, retention, security, and rights fulfilment are equally real, and all depend on data visibility that consent tools alone do not provide.
Ignoring unstructured data. The most sensitive personal information often lives in unstructured formats. Governance programmes that cover only structured databases miss a significant portion of their compliance obligation.
No ownership model. Data governance without assigned ownership is governance on paper. If no one is accountable for a dataset's accuracy, retention, and access controls, no one will enforce them.
Fragmented governance across teams. When privacy, security, legal, and IT each maintain their own partial picture without a shared operational view, governance gaps are inevitable.
Manual classification at enterprise scale. At scale, manual classification produces inconsistency, misses edge cases, and consumes compliance team capacity better spent on governance decisions.
No continuous monitoring. A governance programme that reviews the data landscape periodically will always operate on stale information. Compliance drift is a direct consequence.
The Future of Privacy Governance in India
DPDP has shifted the governance conversation in India from compliance formality to operational discipline. As enforcement matures and organisational data environments grow more complex, the gap between organisations with strong data visibility and those without will widen. A few directions are already clear.
AI governance is becoming a category of its own. As enterprises adopt AI tools for customer service, fraud detection, credit assessment, and personalisation, the data these tools process and generate needs to be governed under the same DPDP obligations as source data. AI governance is an extension of privacy governance, not a separate workstream.
Real-time privacy operations are replacing periodic compliance. The organisations building governance programmes today that will hold up under enforcement are not the ones with the most thorough annual audits. They are the ones with the most current, accurate operational visibility.
Privacy engineering is moving upstream. Data minimisation by design, purpose limitation built into system architecture, privacy impact assessments before product launches. These reflect a governance culture that treats privacy as an operational constraint rather than a retrospective check.
Machine-readable governance, policies and controls expressed in formats that systems can enforce automatically are the direction enterprise governance is heading. Organisations that invest now in the infrastructure to support this will have a material compliance advantage as regulatory expectations rise.
The organisations that succeed under DPDP will not be the ones with the longest privacy policies. They will be the ones who can answer the fundamental question at any point, for any audit: we know what personal data we hold, where it is, why we have it, who can access it, and what happens to it. That starts with seeing the data clearly.
Conclusion
DPDP compliance is built on a foundation that most organisations have not yet fully laid. Consent management, rights workflows, and breach notifications are visible compliance activities. What makes them work or fail is data visibility. Discovery finds the data. Classification determines how it must be governed. Mapping shows how it moves. The personal data inventory connects all three into an operational governance backbone. Automation and DSPM make that backbone sustainable at enterprise scale.
Organisations that build this foundation will find that DPDP compliance becomes progressively more manageable where governance decisions are grounded in accurate information, obligations can be consistently met, and audit evidence is always available. Organisations that skip the foundation will find that each compliance exercise requires rebuilding context from scratch, each incident response is slower than it should be, and the gap between documented and actual compliance posture keeps growing.
Privy by IDfy is built to be that foundation, bringing discovery, classification, mapping, and governance into one connected platform designed specifically for the DPDP compliance reality of Indian enterprises. Contact us at shivani@idfy.com. We would be happy to help.

Discover how automated data discovery tools and machine learning are revolutionizing data classification and PII detection.

On 8th October, at the Global Fintech Fest in Mumbai, regulators and industry leaders debated how fintechs can navigate the DPDPA era. From consent orchestration to purpose mapping and trust accountability, DPDPA compliance will test how fintechs build visibility and integrity into India’s digital finance ecosystem